Median Ages#
Show code cell source
# Import packages
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.colors as clr
import seaborn as sns
import plotly.graph_objects as go
# Read data from file
niger = pd.read_csv("data/Niger-2022.csv")
japan = pd.read_csv("data/Japan-2022.csv")
# Prepare to plot
niger["M"] = -niger["M"]
japan["M"] = -japan["M"]
# Plot
fig, ax = plt.subplots(1, 2, sharey=True, figsize=(10, 5))
sns.barplot(ax=ax[0], x="F", y="Age", data=niger, color="lightcoral")
sns.barplot(ax=ax[0], x="M", y="Age", data=niger, color="steelblue")
sns.barplot(ax=ax[1], x="F", y="Age", data=japan, color="lightcoral")
sns.barplot(ax=ax[1], x="M", y="Age", data=japan, color="steelblue")
ax[0].invert_yaxis()
ax[0].axis("off")
ax[1].axis("off")
plt.show()
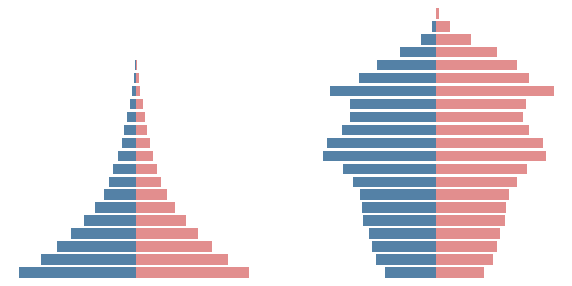
Population pyramid of Niger (left) and Japan (right) in 2022.
Apr, 2023
Interactive visualization
Background#
Given a certain group, how many people are older than you? And how many are younger than you? When you are a newborn, everybody else is older than you. When you are the oldest one, everybody else is younger than you. In between, there will be a percentage of people who are older than you, and a complementary percentage who are younger than you.
The median age is defined so that 50% of the people are older and 50% are younger. The global average median age was 30 years in 2021 – half of the world population was older than 30 years, and the other half was younger. Japan has the highest median age at almost 49 years. One of the lowest is Niger at some 15 years. The median age in Spain is around 44 years.
When I turned 49 last year, it was clear to me that I had already left behind half of my life (life expectancy is some 84 years here). But population is aging in my town and I wondered where I was among my fellow citizens. It could be the case that even if I had left behind the middle age, I was still around the median age!
The data#
Instead of downloading the CSV, I provided the URL from https://www.gipuzkoairekia.eus/ to directly access the data: population of Urretxu in 2022 according to the age, gender and neighbourhood.
Show code cell source
# Define URL of the data
url = 'https://www.gipuzkoairekia.eus/es/datu-irekien-katalogoa/-/openDataSearcher/download/downloadResource/a4085d92-8e7e-4a2c-9472-16a2b7aa9a4f'
# Read the data
pop = pd.read_csv(url,
encoding="iso-8859-1",
sep=";",
on_bad_lines="skip",
usecols=["NOMBRE CALLE", "EDAD", "CANTIDAD MUJERES", "CANTIDAD HOMBRES"])
print(pop)
NOMBRE CALLE EDAD CANTIDAD MUJERES CANTIDAD HOMBRES
0 AREIZAGA 1 1 0
1 AREIZAGA 2 2 0
2 AREIZAGA 3 0 2
3 AREIZAGA 4 2 0
4 AREIZAGA 5 0 2
... ... ... ... ...
1799 BASAGASTI KALEA 78 1 0
1800 BASAGASTI KALEA 79 0 0
1801 BASAGASTI KALEA 80 0 0
1802 BASAGASTI KALEA >80 2 1
1803 BASAGASTI KALEA 000 0 2
[1804 rows x 4 columns]
Data validation#
Unfortunately, the number of the people over the age of 80 is aggregated and appears with the label “>80”. I will replace the label to “81”, and make it a number. I will consider that the people over 80 are all of them 81 years old (yes, it will look strange in the graphic representations but further information is missing).
Show code cell source
# Replacement
pop = pop.replace(">80", "81")
# Convert to integer
pop["EDAD"] = pop["EDAD"].astype(int)
# Show dataframe info
pop.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1804 entries, 0 to 1803
Data columns (total 4 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 NOMBRE CALLE 1804 non-null object
1 EDAD 1804 non-null int32
2 CANTIDAD MUJERES 1804 non-null int64
3 CANTIDAD HOMBRES 1804 non-null int64
dtypes: int32(1), int64(2), object(1)
memory usage: 49.5+ KB
Population pyramid#
Let’s build the population pyramid for my town.
Show code cell source
# Group by age and sum women and men quantities
pop_ages = pop.groupby("EDAD")[["CANTIDAD MUJERES", "CANTIDAD HOMBRES"]].sum()
# Establish age intervals for population pyramid
bins = pd.IntervalIndex.from_tuples([(i, i + 4) for i in range(0, 85, 5)], closed='both')
# Create new column with intervals
pop_ages["interval"] = pd.cut(pop_ages.index, bins)
# Group by intervals
pop_ages_pyr = pop_ages.groupby("interval")[["CANTIDAD MUJERES", "CANTIDAD HOMBRES"]].sum()
print(pop_ages_pyr)
CANTIDAD MUJERES CANTIDAD HOMBRES
interval
[0, 4] 88 95
[5, 9] 110 124
[10, 14] 196 205
[15, 19] 194 212
[20, 24] 180 203
[25, 29] 153 157
[30, 34] 140 140
[35, 39] 138 175
[40, 44] 195 204
[45, 49] 301 288
[50, 54] 260 274
[55, 59] 272 289
[60, 64] 235 260
[65, 69] 206 176
[70, 74] 180 161
[75, 79] 167 137
[80, 84] 314 174
Show code cell source
# Prepare to plot
pop_ages_pyr = pop_ages_pyr.reset_index()
pop_ages_pyr["CANTIDAD HOMBRES"] = - pop_ages_pyr["CANTIDAD HOMBRES"]
# Plot
fig, ax = plt.subplots(figsize=(6, 6))
sns.barplot(ax=ax, x="CANTIDAD MUJERES", y="interval", data=pop_ages_pyr,
color="lightcoral", order=pop_ages_pyr["interval"])
sns.barplot(ax=ax, x="CANTIDAD HOMBRES", y="interval", data=pop_ages_pyr,
color="steelblue", order=pop_ages_pyr["interval"])
ax.tick_params(axis='x', labelsize=11, rotation=0)
ax.tick_params(axis='y', labelsize=11)
ax.set_title("Population pyramid (Urretxu, 2022)", fontsize=14)
ax.set_xlabel("quantity", fontsize=13)
ax.set_ylabel("age group (years)", fontsize=13)
sns.despine()
ax.set_xticks(range(-300, 400, 100), labels=[300, 200, 100, 0, 100, 200, 300])
ax.set_xlim(-400, 400)
ax.invert_yaxis()
ylabels = [str(i)+"-"+str(i + 4) for i in range(0, 85, 5)]
ylabels[-1] = ">=80"
ax.set_yticks(range(0, 17), labels=ylabels)
ax.text(225, 5, "female", fontsize=13, fontweight='bold', color="lightcoral")
ax.text(-350, 5, "male", fontsize=13, fontweight='bold', color="steelblue")
plt.show()
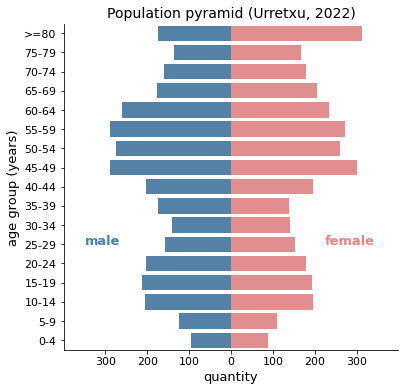
Certainly, this pyramid is closer to the Japanese than to the pristine one of Niger. In fact, it looks like a house of cards that is going to fall apart, with that sort of beret on top of it. The effect is due to the aggregation of the elderly mentioned earlier, it is strange that the individual ages of those over 80 are not attended to, because they make up a large group. This omission feels inconsiderate nowadays. Among women, those over 80 constitute the largest group in town.
Median age#
I was interested in calculating the median age, so I will compute total numbers adding men and women, then group by age and sum numbers creating a new dataframe.
Show code cell source
# Create new column adding women and men numbers
pop_ages["TOTAL"] = pop_ages[["CANTIDAD MUJERES", "CANTIDAD HOMBRES"]].sum(axis=1)
# Use just total values
pop_ages_all = pop_ages[["TOTAL"]]
# Append end of ages: 82 years, 0 people
pop_ages_all = pd.concat([pop_ages_all,
pd.DataFrame({'TOTAL': [0]}, index=[82])])
print(pop_ages_all)
TOTAL
0 22
1 49
2 31
3 39
4 42
.. ...
78 53
79 58
80 41
81 447
82 0
[83 rows x 1 columns]
Show code cell source
# Calculate total population
pop_total = pop_ages_all["TOTAL"].sum()
print(f"Total population in 2022 -> {pop_total}")
Total population in 2022 -> 6603
Now I am going to calculate the number (and percentage) of people younger and older for each age.
Show code cell source
# Sum number of younger population
pop_ages_all["younger"] = pop_ages_all["TOTAL"].shift(1).cumsum().fillna(0)
# Calculate number of older population
pop_ages_all["older"] = pop_total - pop_ages_all["younger"]
# Calculate percentages
pop_ages_all["younger_%"] = 100 * pop_ages_all["younger"] / pop_total
pop_ages_all["older_%"] = 100 * pop_ages_all["older"] / pop_total
# Round remove decimal places
pop_ages_all = pop_ages_all.round(0)
print(pop_ages_all)
TOTAL younger older younger_% older_%
0 22 0.0 6603.0 0.0 100.0
1 49 22.0 6581.0 0.0 100.0
2 31 71.0 6532.0 1.0 99.0
3 39 102.0 6501.0 2.0 98.0
4 42 141.0 6462.0 2.0 98.0
.. ... ... ... ... ...
78 53 6004.0 599.0 91.0 9.0
79 58 6057.0 546.0 92.0 8.0
80 41 6115.0 488.0 93.0 7.0
81 447 6156.0 447.0 93.0 7.0
82 0 6603.0 0.0 100.0 0.0
[83 rows x 5 columns]
Finally, let’s find out the median age: the age at which older people than you drops for the first time below 50%.
Show code cell source
# Calculate the medium age
medium_age = pop_ages_all[pop_ages_all["older_%"] < 50].index[0]
print(f'Median age -> {medium_age} years')
Median age -> 49 years
Show code cell source
# Create the basic figure
fig = go.Figure()
# Add graphs
fig.add_trace(go.Scatter(
x=pop_ages_all.index,
y=pop_ages_all["older_%"],
name='older',
mode='lines', line={'color': 'goldenrod', 'width': 0},
fill="tozeroy", # fillcolor='rgba'+str(clr.to_rgba('goldenrod')),
hovertemplate='older: %{y:.0f}%<extra></extra>'))
fig.add_trace(go.Scatter(
x=pop_ages_all.index,
y=pop_ages_all["younger_%"],
name='younger',
mode='lines', line={'color': 'forestgreen', 'width': 0},
fill="tozeroy", # fillcolor='rgba'+str(clr.to_rgba('forestgreen')),
hovertemplate='younger: %{y:.0f}%<extra></extra>'))
# Create annotations
annotation_1 = {'text': 'older', 'x': 15, 'y': 50, 'showarrow': False,
'font': {'size': 18, 'color': 'black'}}
annotation_2 = {'text': 'younger', 'x': 65, 'y': 50, 'showarrow': False,
'font': {'size': 18, 'color': 'black'}}
# Update layout
fig.update_layout({
'title': {'text': 'Population distribution (Urretxu, 2022)'},
'width': 700,
'height': 500,
'plot_bgcolor': 'white',
'annotations': [annotation_1, annotation_2],
'showlegend': False,
'xaxis': {'range' : [0, 100], 'title': {'text': 'age'},
'tickvals': list(range(0, 110, 10))},
'yaxis': {'range' : [0, 100], 'title': {'text': 'population'},
'tickvals': list(range(0, 110, 25)),
'ticktext':['0 %','25 %', '50 %', '75 %', '100 %']},
'hovermode': 'x unified',
})
# Show the plot
fig.show()
Here we have it: it turns out that when I turned 49 last year (2022), I was also turning the median age for my town!
So I am not that old, considering.